Leaderboard
| Model | Type | Agent | O-M2W Judge | Rubric Avg | Perfect | Avg. Steps | Traj. Eff. |
|---|
Notes.
Rubric Avg treats each task rubric pair as an independent observation and averages them.
Perfect marks a task as passing only if every rubric is satisfied.
O-M2W Judge is the trajectory-level holistic LLM judge from Online-Mind2Web.
Avg. Steps is the mean number of interaction steps the agent takes per task, where lower is more efficient.
Traj. Eff. (Trajectory Efficiency) is (1/N) · Σ sᵢ / nᵢ, where sᵢ is the averaged rubric score on task i and nᵢ is the number of agent steps. Higher values mean stronger outcomes achieved in fewer steps.
Agent distinguishes CUA (computer-use agents that consume screenshots and emit GUI actions) from Terminal agents that drive the browser by writing code (e.g. Playwright).
Cells marked — are metrics not reported by the source. CUA scores are reproduced from Table 2 of the paper; WebWright is reproduced from the WebWright article.
Breakdown by difficulty
Tasks come in three tiers. Easy tasks use at most 5 steps and 3 domains, medium tasks use 6 to 8 steps or 4 or more domains, and hard tasks exceed both thresholds. Each bar shows the perfect rubric rate, the share of tasks a model solves with every rubric item satisfied.
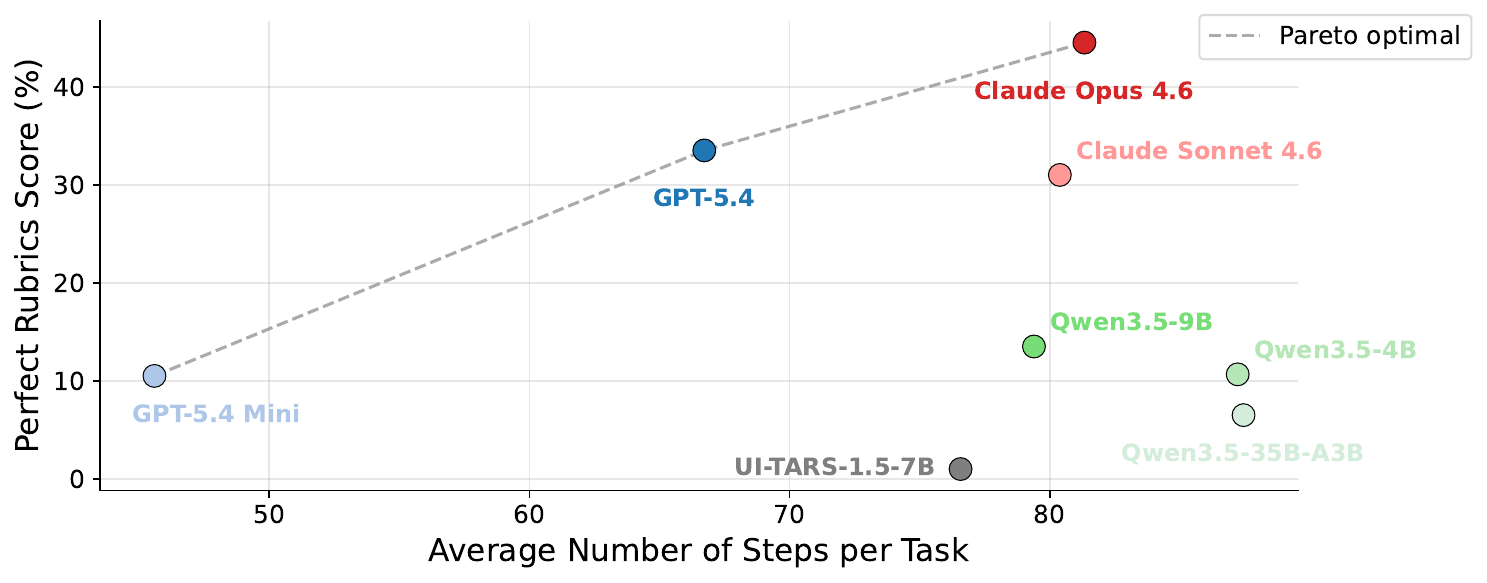
Steps vs perfect score
Each model's perfect rubric rate plotted against its average number of steps per task, with the Pareto frontier overlaid. Opus 4.6 sits at the capability end of the frontier, with GPT-5.4 and GPT-5.4 Mini trading off step budget for perfect rate. Each additional step of compute buys progressively smaller gains.