Abstract
Existing web agent benchmarks have largely converged on short, single-site tasks that frontier models are approaching saturation on. However, real-world web use consists of long-horizon, multi-site workflows. Common web navigation tasks such as comparing products across different domains, planning trips across multiple services, or summarizing information from multiple search queries require sustained context and cross-site reasoning over potentially hours of browsing.
To capture and evaluate such behaviors, we introduce Odysseys, a benchmark of 200 long-horizon web tasks derived from real-world browsing sessions and evaluated on the live Internet. We find that binary pass/fail evaluation is inadequate for long-horizon settings and introduce a rubric-based evaluation, annotating each Odysseys task with a set of graded rubric checkpoints. This yields higher agreement with humans and provides a more fine-grained signal than commonly used trajectory-level LLM-as-a-judge evaluation metrics.
We evaluate several leading frontier models and find that the strongest achieves a success rate of 44.5%, leaving substantial headroom for future improvements. Beyond task success, we argue that efficiency is a first-class concern for long-horizon agents, and introduce a Trajectory Efficiency metric (rubric score per step) on which even frontier agents reach only 1.15%, leaving room for agents that can succeed efficiently and not merely eventually. Odysseys isolates the evaluation of long-horizon proficiency in open-web environments and provides a realistic benchmark for measuring progress towards computer-use agents that can productively operate for hours.
1 · Introduction
Recent large language models can now function as computer-use agents. They browse websites, interpret screenshots, click interface elements, and execute multi-step instructions in human-facing software. However, current benchmarks largely evaluate these capabilities in short, tightly scoped episodes, leaving a key regime underexplored. That regime is long-horizon web workflows that unfold across many pages, tabs, and domains. This limitation matters because real-world web use is rarely confined to a single page or a single domain. Many common tasks require extended interaction over multiple sites, such as comparing products across retailers, planning travel across booking platforms, or gathering information from search results and synthesizing it into a downstream deliverable. Solving such tasks requires more than local grounding or short-term action selection. Agents must maintain context over long horizons, reason across heterogeneous websites, decompose open-ended goals into subproblems, and decide when to stop exploring and produce an output.
Towards this goal, we introduce Odysseys, a benchmark of 200 long-horizon web tasks derived from real-world browsing behavior and evaluated on the live Internet. Each task requires agents to execute multi-step workflows across multiple websites. The tasks cover realistic activities and are grounded in annotated human browsing journeys rather than synthetic templates. We also identify the inadequacy of current trajectory-level LLM-as-a-judge evaluation metrics, commonly used in computer-use benchmarks. These metrics become increasingly noisy with longer and more complex trajectories. To address this, we propose a rubric-centric LLM-as-a-Judge evaluation scheme in which each task is decomposed into a set of verifiable requirements. This provides a more informative measure of partial completion and yields stronger agreement with human judgments than trajectory-level grading.
We evaluate leading frontier and open-weight computer-use agents in Odysseys. The strongest model we tested (Opus 4.6) achieves 44.5% perfect task success, indicating substantial headroom for progress. Our analysis shows that current agents struggle with core aspects of long-horizon web navigation, including sustained planning, cross-site coordination, and balancing information gathering against completing user requested deliverables. We also observe that several compelling strategies emerge, suggesting that current agents have developed flexible behaviors for operating in open-ended computer environments.
Example trajectories of frontier agents on Odysseys tasks.
Full task prompt given to the agent
2 · The Odysseys Dataset
The Odysseys dataset consists of 200 long-horizon, multi-site web tasks designed to evaluate web agents on realistic browsing workflows. Each task begins from a Google search page and requires the agent to navigate across multiple websites to complete complex, multi-step objectives such as comparing products across e-commerce platforms, planning travel itineraries, or setting up video playlists and watching lectures.
2.1 Collection process
We recruit 248 participants based in the US and UK through the Prolific crowdsourcing platform and provide them with a desktop application that reads their Chrome browsing history and exposes an interface for annotating that history into web agent tasks. The application segments browsing activity into singular tasks with corresponding URLs using Chrome's Journey algorithm. For each journey, participants annotate four things. (1) A key URL representing the success state. (2) An automation preference indicating whether they would want the task automated. (3) A task label describing the activity as they would prompt an AI tool. (4) A feasibility judgment that marks whether the task would be possible to complete. The collection yields 2,380 labeled journeys spanning domains such as comparison shopping, travel planning, media consumption, and information research.
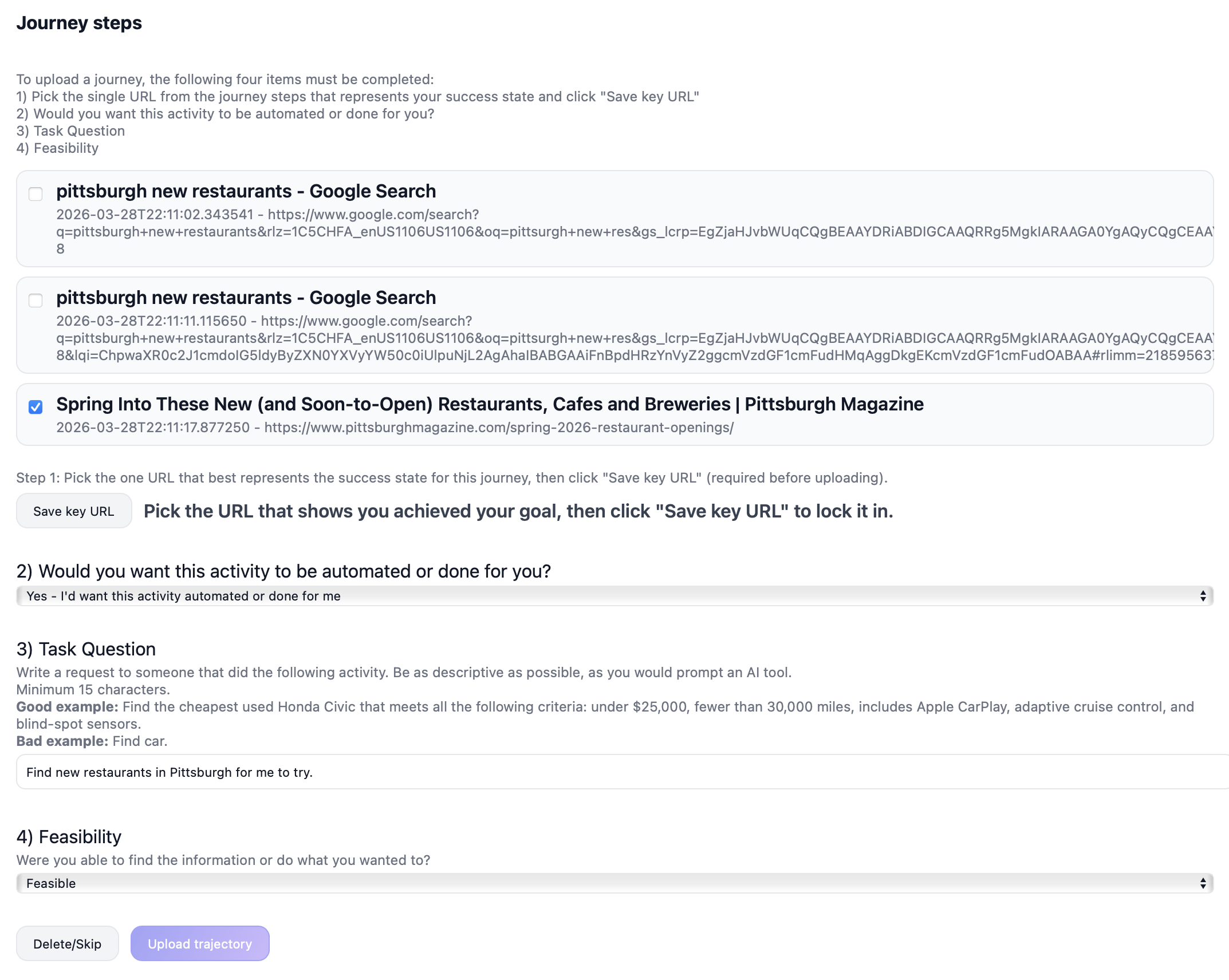
2.2 From journeys to Odysseys
Raw journey labels are noisy, as participants may submit labels unrelated to the URLs, underspecify tasks, or provide vague descriptions. We address this through a two-stage refinement process combining LLM screening with manual review. After filtering for label accuracy, feasibility, login requirements, and overall quality, 696 high-quality journeys (29.2%) remain.
The resulting journeys represent real browsing behavior but are generally short subtasks due to Chrome's journey segmentation. To compose them into realistic long-horizon tasks, we cluster related journeys by embedding similarity and use GPT-5.4 to arrange subsets into coherent multi-step workflows. For each composed task, the LLM generates a natural-language prompt, a step plan, a rubric with verification procedures, and a self-assessed coherence score. Each source journey is used at most three times across the benchmark to prevent over-representation. We reject generated tasks that span fewer than two sites, have incomplete rubrics, or score below 2/5 on coherence. Difficulty is assigned by step count and domain spread. Easy tasks use at most 5 steps and 3 domains. Medium tasks use 6 to 8 steps or 4 or more domains. Hard tasks exceed both thresholds.
In addition to the 90 composed tasks, the authors contribute 30 manually authored long-horizon tasks grounded in real personal queries, following the same schema. We also use an LLM pipeline to generate an additional 80 hard Odysseys tasks. For each journey we provide GPT-5.4 with in-context examples of human-authored long-horizon tasks as inspiration, and candidates are filtered through an LLM judge and human QA. The full generation pipeline is described in the paper appendix. The final benchmark contains 200 tasks in total.
2.3 Final review
Every task, composed or manually authored, undergoes a two-pass review using a dedicated QA interface. In the first pass, the authors verify prompt coherence, trace each component to its source journey, and ensure that rubric items are unambiguous and actionable. All prompts that reveal any potential personally identifiable information (PII) are rewritten or removed. In the second pass, an LLM-augmented pipeline uses a web-search tool to confirm site accessibility and step feasibility, and a human adjudicates flagged issues. Tasks that fail in either pass are revised or removed before entering the benchmark.
2.4 Dataset statistics
The benchmark comprises 200 tasks spanning three difficulty levels. There are 45 easy, 46 medium, and 109 hard tasks. Task instructions average 265.8 words (median 264.5, range 76 to 387), reflecting the detailed, multi-step nature of real-world web workflows.
3 · Rubric evaluation
Prior work on computer-use agents typically uses one of two schemes. The first is execution-based verification, which requires handcrafted task-specific rewards. The second is LLM-as-a-judge over entire agent trajectories, in which an LLM takes in the screenshots and actions of an agent execution trace and outputs a score or pass/fail metric. However, both approaches are unsuitable for Odysseys. Crafting rules-based rewards for every long-horizon task is infeasible, and holistic trajectory-level judges become increasingly noisy as trajectories grow longer and more complex. Inspired by prior work on rubrics and checklists for evaluating and training language models, we investigate a rubric-based evaluation for Odysseys tasks.
3.1 Rubric construction
For each task we generate a structured set of rubric items that evaluate partial progress. Rubrics are generated alongside the task during LLM composition. For each rubric item, the model produces a requirement, a single verifiable checkpoint, and a verification description of how a grader should determine whether the requirement has been accomplished. Tasks contain between 3 and 12 rubric items. All rubric items are verified by an author for correctness and relevance to task completion, and we also run an LLM augmented with a text-based web-search tool to cross-check verification criteria against the live web.
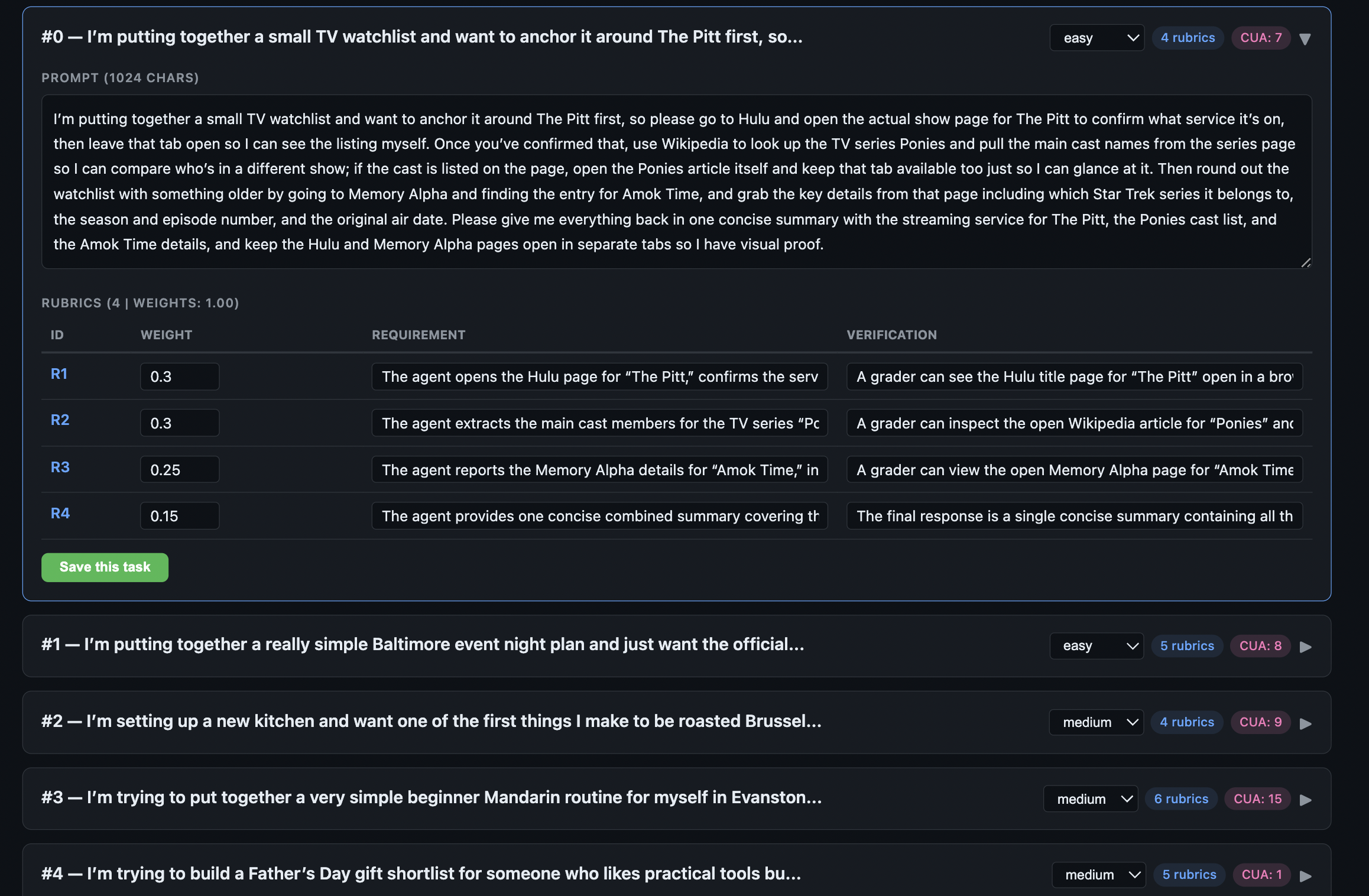
3.2 Scoring
To evaluate model performance with rubrics, we prompt an LLM as a judge (gemini-3.1-flash-lite-preview in all experiments) given each step's screenshot and action, together with a single rubric item's requirement and verification. Each rubric is considered satisfied (score of 1) if any step in the trajectory satisfies it, and 0 otherwise. We report two metrics per task. Averaged is the mean rubric score over the task's rubric items. Perfect is a binary score that is 1 if and only if every rubric for the task is satisfied.
3.3 Trajectory Efficiency
Raw rubric scores capture what an agent accomplished but not how efficiently it performs. This matters for Odysseys in particular, as a 100-step trajectory takes Opus 4.6 roughly 30 minutes of wall-clock time to complete, far longer than a human would realistically wait for any of these tasks to finish. Two agents may reach the same rubric score, but one that does so in 30 steps delivers a dramatically better user experience than one that does so in 100. To quantify this, we report Trajectory Efficiency, defined as the per-task ratio of averaged rubric score to step count, averaged over all tasks.
where si is the averaged rubric score for task i and ni is the number of agent steps taken on that task. Unlike the Success weighted by Path Length metric from Vision-Language Navigation, we do not know the oracle number of steps required for each task and therefore cannot normalize by an optimal trajectory length. Higher Trajectory Efficiency indicates that an agent achieves strong outcomes in fewer steps, penalizing trajectories that eventually succeed only after substantial wasted effort.
Step count in the denominator counts environment steps, which need not coincide with LLM calls. One environment step corresponds to one observation action loop within the web agent runner. GPT-5.4 averages 2.03 actions per call (49.1% of calls return two or more actions, up to 24 in a single turn), whereas Opus 4.6 returns exactly one action per call in every task. At equal rubric score, GPT-5.4 therefore spends roughly half as many model round-trips, materially reducing wall-clock time per task. This gap suggests that training or prompting for multi-action batching is a practical, orthogonal lever for efficiency on long-horizon tasks, complementary to raising per-step success rates.
3.4 Human agreement
To determine the effectiveness of rubric-based evaluation, we measure the agreement between automated LLM judges and human annotations at three levels of granularity. At the finest level, rubrics (average) treats each task rubric pair as an independent observation. For the rubrics (perfect) metric, a task is scored as passing only if every one of its rubrics are satisfied. At the trajectory level, we run the LLM judge from Online-Mind2Web, which issues a holistic pass/fail judgment based on the agent's action trajectory. We collected human annotations of 120 Opus 4.6 trajectories and compute agreement via Cohen's κ, F1, and accuracy against the collected labels.
Across all metrics, rubric-based evaluation substantially outperforms the trajectory judge.
Rubrics additionally provide partial credit for weaker models, which may otherwise receive only zero scores under the trajectory-level judge. This also introduces a meaningful reward signal for training weaker models with reinforcement learning, which is a promising direction for future work.
4 · Experiments
We benchmark several frontier API-based models and open-weight models on Odysseys. Each model is implemented with its own recommended settings for computer-use, and we launch them in the same virtual Ubuntu environments from OSWorld. The primary application used by the models is Google Chrome, although some models also occasionally choose to use other applications such as LibreOffice to generate a report. We only benchmark models that have general computer-use abilities and do not test models trained only for web navigation, as many Odysseys tasks involve subtasks that are infeasible for web-navigation-only models (for example, maintaining multiple tabs).
All experiments run under identical settings. We limit the number of steps to at most 100 and use the maximum reasoning effort possible (if any). At 100 steps, Opus 4.6 takes approximately 30 minutes and $2.50 per task. We use the OSWorld runner, and each model starts with a Google Chrome window at the provided starting URL for the task (if any). Models have access to the full Google Chrome interface and are allowed to open tabs, save files, or perform any action supported by the virtual machine.
We evaluate all models with the proposed rubric-based evaluation (Sec. 3). The best frontier computer-use models, Opus 4.6 and GPT-5.4, achieve the strongest scores, with Opus 4.6 scoring slightly better across most metrics. GPT-5.4 models tend to use fewer steps in general, which translates into higher Trajectory Efficiency (1.15 versus 1.06 for Opus 4.6) despite a lower perfect rate. Open-weight models trail starkly behind frontier models; surprisingly, the smaller Qwen-3.5-VL-9B and Qwen-3.5-VL-4B variants outperform the larger Qwen-3.5-VL-35B-A3B mixture-of-experts model on Odysseys.
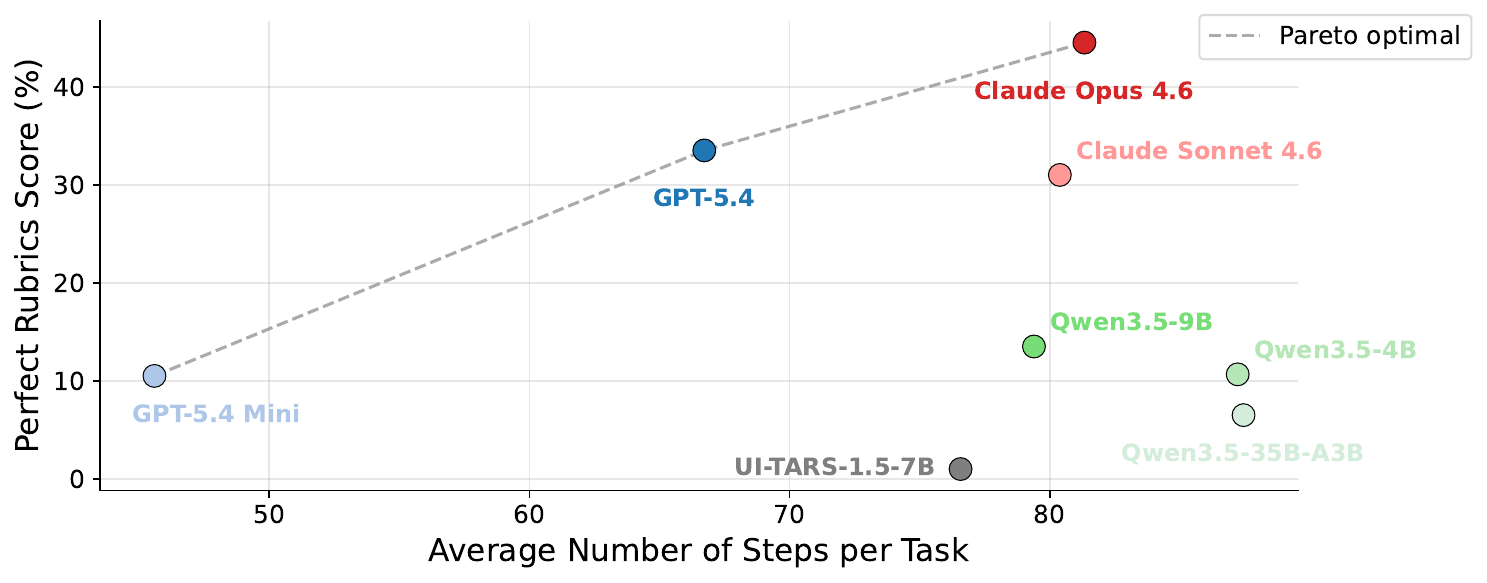
Plotting perfect rubric rate against average steps per task makes the capability and efficiency trade-off explicit. Three models lie on the Pareto frontier. GPT-5.4 Mini sits at the low-cost end (41.7 steps, 10.5% perfect), GPT-5.4 in the middle (64.4 steps, 33.5%), and Opus 4.6 at the capability end (81.3 steps, 44.5%). Moving rightward along the frontier, each additional increment of step budget yields progressively smaller gains in perfect rate, the same diminishing-returns pattern observed in the step-scaling curves below. Sonnet 4.6 is notable as a non-frontier point. Despite competitive rubric-average scores, it is Pareto-dominated by both Opus 4.6 and GPT-5.4, which achieve higher perfect rates with fewer steps. Open-weight models lie well inside the frontier, spending more steps for substantially lower perfect rates, consistent with a capability ceiling rather than a step-budget bottleneck.
4.1 · Scaling with step budget
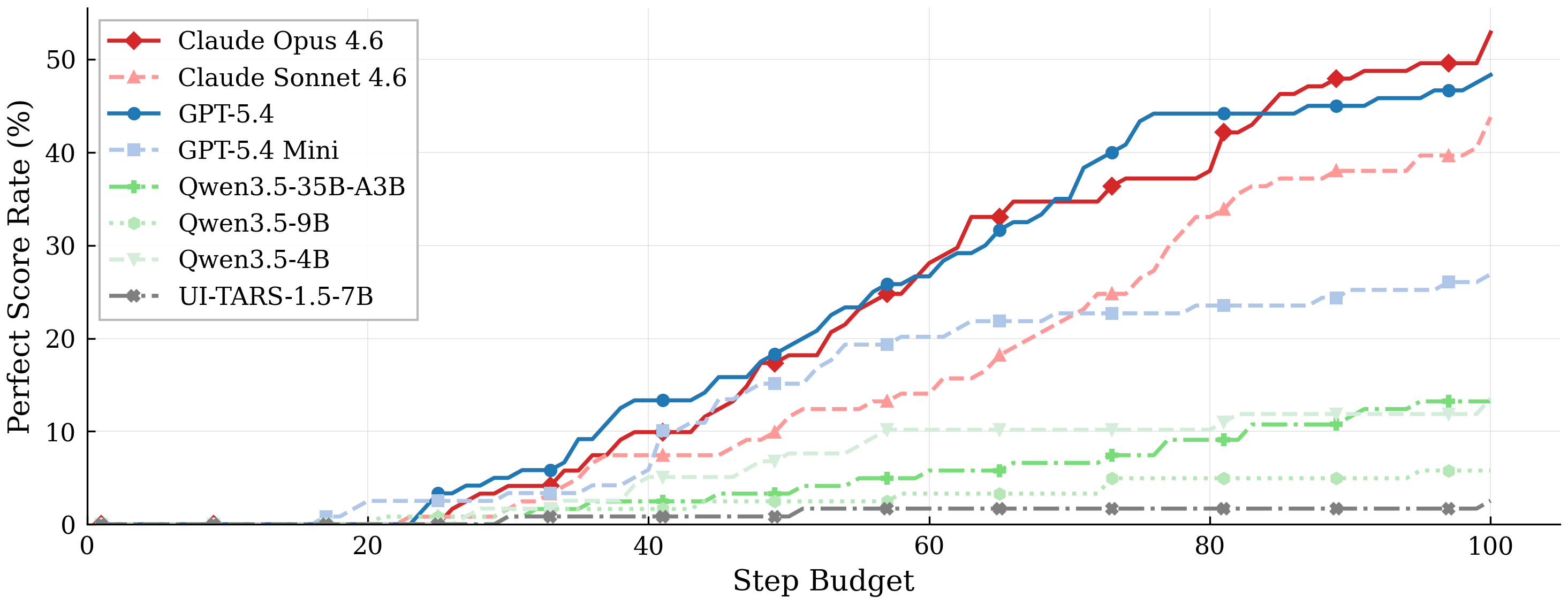
Figure 4 shows how task completion improves as models are allowed more interaction steps. All models exhibit a broadly sigmoidal scaling curve. Perfect score rates remain near zero for the first ~15 steps, reflecting the minimum number of interactions needed to complete the simplest Odysseys tasks. Rates then rise steadily through the 20 to 70 step range as progressively harder tasks are fully solved, before the rate of improvement tapers past ~80 steps. The two frontier models, Claude Opus 4.6 and GPT-5.4, reach substantially higher asymptotic perfect score rates (~44.5% and ~33.5% respectively) and climb more steeply through the mid-range, indicating greater per-step efficiency in addition to a higher capability ceiling. In contrast, GPT-5.4 Mini and the Qwen-3.5-VL variants exhibit markedly shallower slopes and lower asymptotes, suggesting their shortfall reflects fundamental capability gaps rather than insufficient step budgets.
4.1.1 Increasing the maximum to 200 steps
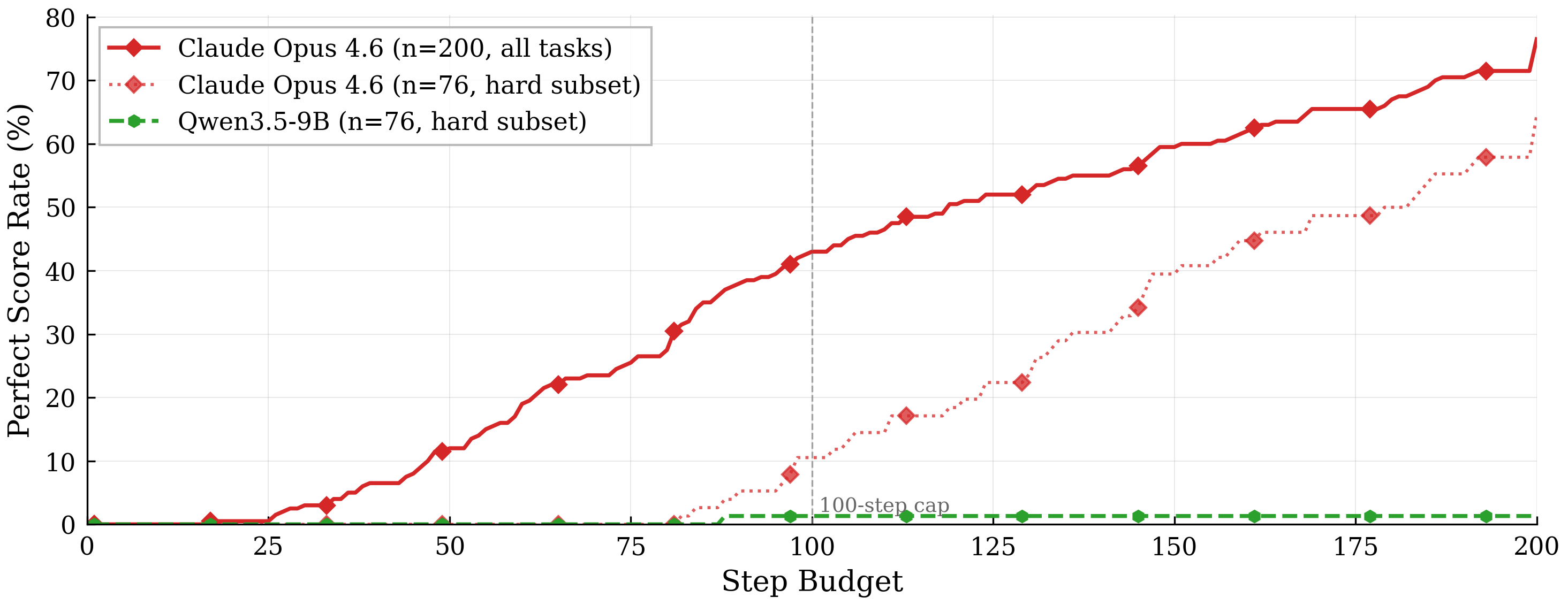
To probe whether the 100-step cap is the binding constraint on the eventual success of frontier models, we run Opus 4.6 with a 200-step budget on all 200 tasks. The perfect task rate increases from 44.5% in a 100-step budget to 76.5% in 200 steps (86/200 → 153/200), and the fraction of runs that exceed the step limit in the 200-step run is 14.5% (29/200). Figure 5 shows that Opus's curve continues to rise monotonically across the full range, demonstrating that additional step budget translates into meaningful gains for capable agents on genuinely long-horizon tasks. Even under the optimistic assumption that every run that hit the 200-step cap would eventually reach perfect given unbounded steps, Opus 4.6 tops out at 86.0% on the 200-task set, indicating that at least approximately 14% of tasks fail for reasons other than insufficient test-time compute.
4.1.2 Failure modes that persist at 200 steps
We find that three qualitative failure modes account for the majority of residual errors in Opus 4.6's performance even at 200 steps. (1) Information gathering without deliverable production. The largest category involves the agent thoroughly browsing and collecting data but never compiling the required summary, spreadsheet, or document before terminating. (2) Abandoning progress for an incorrect programmatic shortcut. On research-heavy tasks, Opus 4.6 occasionally abandons UI interaction mid-trajectory in favor of scripting a terminal-based solution that then fails to recover. (3) High-fanout tasks that run out of breadth. Tasks requiring parallel coverage of many items tend to stall after completing a subset. These failures indicate that current agents struggle with the structure of long-horizon tasks and would likely benefit from sub-agents or explicit step-aware planning.
4.1.3 Qwen 3.5 flatlines even at 200 steps
Qwen 3.5 exhibits a qualitatively different curve, in that extending the budget from 100 to 200 steps yields essentially zero additional progress. Within the same 200-step comparison described above, Qwen-3.5-VL-9B reaches 1/76 perfect tasks by step 100 and does not solve a single additional task between steps 100 and 200. On the identical 76-task subset, Opus 4.6 gains +55 percentage points (from 10% to 65%) over the same 100-step extension. Only 10.5% of Qwen runs actually hit the 200-step cap, and the optimistic upper bound assuming that all capped runs eventually succeeded is just 11.8%. Qualitatively, Qwen failures differ from Opus's. Rather than running out of budget on a coherent plan, Qwen frequently thrashes between tabs without satisfying any coverage criterion, indicating a capability limit rather than a step-budget limit.
4.2 · Difficulty levels
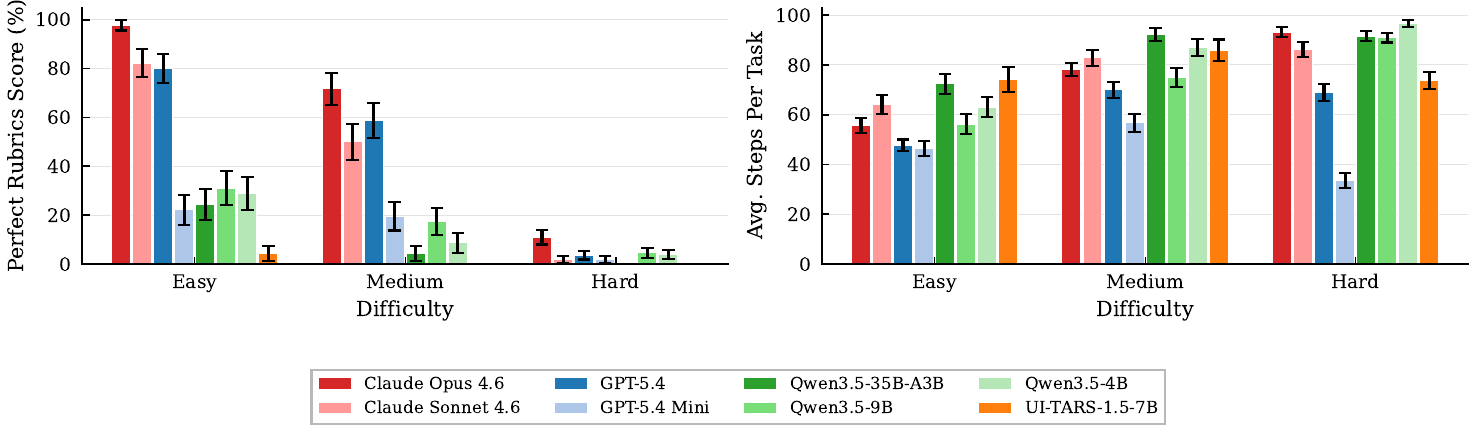
As described in Sec. 2.2, Odysseys tasks are categorized by difficulty level, which is roughly correlated with how many steps are required to solve the task and how many unique website domains it requires traversing. Figure 6 summarizes model performance across these tiers. We observe that performance substantially degrades on hard tasks. Opus 4.6 reaches an 11.0% perfect rate on hard, substantially outperforming GPT-5.4 at 3.7% and the next-best models, all of which sit below 5%. Opus 4.6 and Sonnet 4.6 also tend to use more steps across all difficulty levels, particularly on hard tasks.
4.3 · Unique failure modes per model
All frontier models we tested exhibit distinct failure patterns on long-horizon tasks. Opus 4.6 most commonly fails through over-investment in research. It continues to gather information but does not transition to producing the required deliverable, such as creating the final document, and eventually exhausts the step budget with an empty output artifact. This pattern appears in 6 of its 12 zero-score runs. Opus runs remain productive but incomplete until termination, hitting the 100-step cap on 39% of tasks, while its partial-credit runs average 97.4 steps.
GPT-5.4, by contrast, more often fails through inaction despite correct high-level reasoning. On 4 of its 7 zero-score tasks, it generates long, detailed plans that correctly identify which pages to visit and what information to collect, but then terminates with an empty action after only a few steps, sometimes without any browser interaction at all.
Produces but never delivers
Continues gathering information but never transitions to producing the required deliverable. Exhausts the step budget with an empty output artifact.
6 / 12 zero-score runs · 39% hit 100-step cap · partial-credit runs average 97.4 steps.
Plans correctly, then stops
Generates long, detailed plans that correctly identify which pages to visit, then terminates with an empty action after only a few steps, sometimes without any browser interaction at all.
4 / 7 zero-score tasks.
Both models share a common failure mode on especially broad tasks with many parallel subtasks. Tasks that require visiting 10 to 30 venues, such as planning a trip to every MLB stadium, often cause both models to become stuck in the first phase, such as collecting schedules, without progressing to flight search, hotel selection, or document compilation. All such tasks receive zero scores from both models. This suggests that current agents struggle not only with long sequential horizons but also with high-fanout task structure in which effort must be allocated across many related subtasks, a direction for which models would likely benefit from sub-agents or a multi-agent setup.
4.4 · Surprising capabilities
Both GPT-5.4 and Opus 4.6 exhibit behaviors that are notably sophisticated. GPT-5.4 in particular develops several strategies that repurpose browser and system primitives for information extraction. We observe it using an unprompted strategy for bulk spreadsheet entry. Rather than pasting cell contents directly, it encodes full tables as base64 strings inside its Python action, decodes them at runtime, and pastes the result through the clipboard so that tab and newline delimiters are preserved (Figure 7). We observe this behavior in 8 runs.

pyperclip.copy(_text); pyautogui.hotkey('ctrl', 'v'). This preserves exact tab and newline characters and populates the spreadsheet in a single paste with the correct column mapping.
A second recurring pattern is that when a product page fails to render correctly due to JavaScript errors, the model navigates to the raw HTML through the view-source protocol, searches within the source using ctrl+f, and extracts structured product metadata from embedded JSON-LD markup, including variant identifiers, stock status, and size mappings (Figure 8). We observe this behavior in 23 runs.

margauxny.com rendered blank due to JavaScript failures, GPT-5.4 typed view-source:https://margauxny.com/products/... directly in the address bar, then used ctrl+f to search for variants, InStock, 40.5, and US 9.5 in the raw HTML. From the embedded JSON-LD schema it decoded EU 40.0 = US 9.5, confirmed the SKU was in stock, and reconstructed the direct variant URL, all without the product page ever rendering visually.
Opus 4.6 exhibits a different set of strengths. When target websites return 403 errors, it sometimes falls back to the Wayback Machine by constructing archived URLs and retrieving cached versions of otherwise inaccessible pages (Figure 9). This enables it, for example, to recover class schedule information that would not be available through direct browsing alone.

403 Forbidden. Opus immediately navigated to https://web.archive.org/web/2024/https://coilyoga.com/classes/ and repeated the same strategy for Tower Yoga, successfully retrieving archived pages from June 2024 that contained the full class schedule.
Opus also makes substantially heavier use of middle-click to open links in background tabs without losing its place on the current page, using this interaction 131 times across all runs compared to just 7 for GPT-5.4. In addition, it uses ctrl+f not only to locate information but also to falsify hypotheses about page relevance (Figure 10). After searching for a keyword and observing no matches, it often treats that absence as evidence that the page is unproductive and moves on immediately.
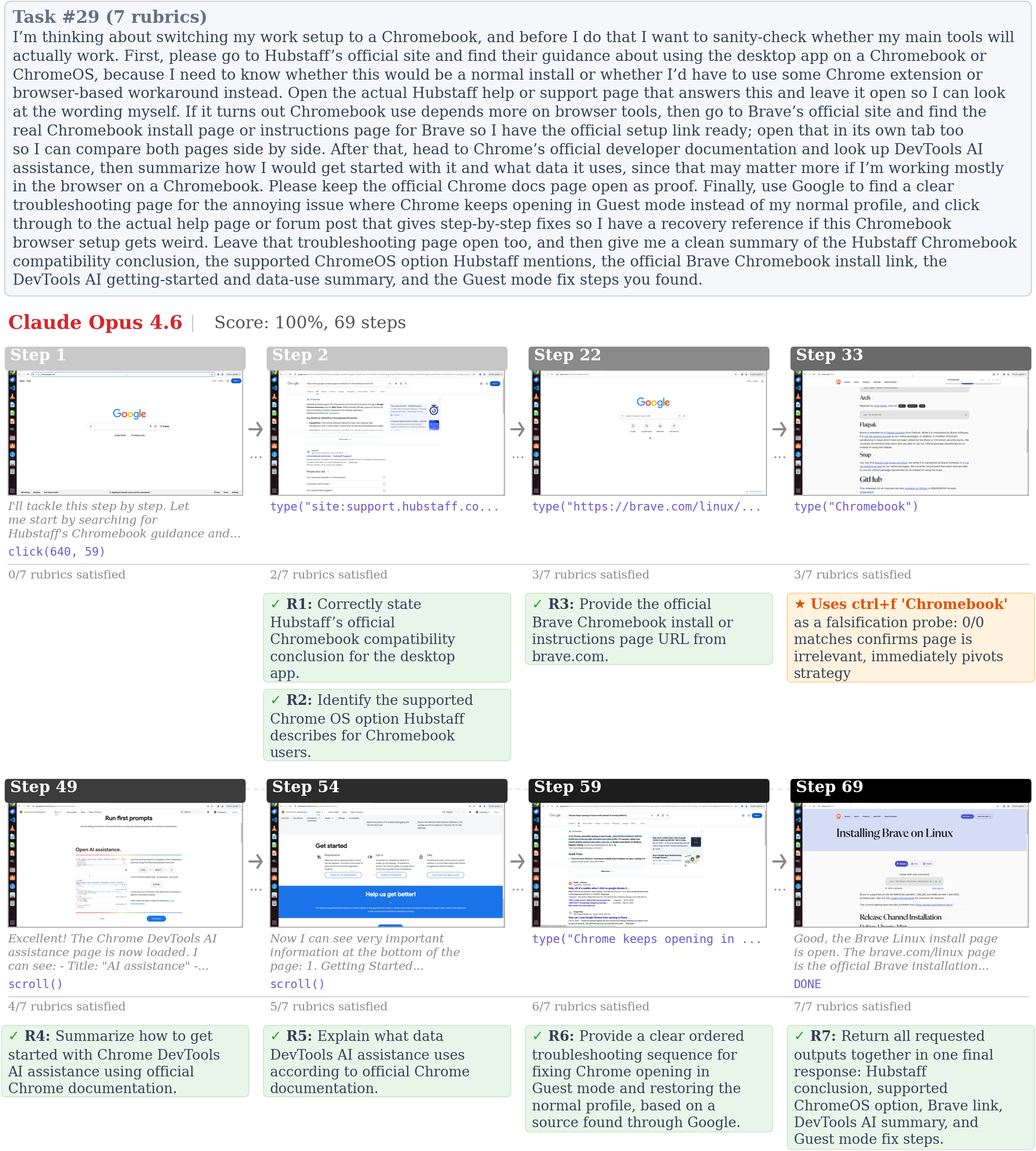
brave.com/linux, Opus used ctrl+f to search for Chromebook and observed 0/0 matches, confirming the page did not cover the topic. Rather than scrolling to verify, it treated the absence of a match as decisive evidence and pivoted immediately.
5 · Conclusion
In this work, we introduced Odysseys, a benchmark for evaluating web agents on realistic long-horizon tasks drawn from real browsing behavior. In contrast to previous web benchmarks that emphasize short, single-site episodes, Odysseys focuses on long multi-site workflows that require sustained planning, navigation, and cross-page reasoning. We demonstrated that existing trajectory-level evaluation methods are insufficient for long-horizon trajectories, and proposed rubric-based evaluations that decompose long-horizon success into verifiable intermediate outcomes, yielding substantially higher agreement with human judgment.
Our experiments show that, despite strong recent progress in computer-use agents, long-horizon web interaction is far from solved. Even the best frontier models achieve only approximately 44.5% perfect-task success, with performance dropping sharply on harder tasks and plateauing as step budgets increase. Moreover, raw success rate understates how far current systems are from being practically usable. A 100-step Opus trajectory already takes roughly 30 minutes of wall-clock time, well beyond an efficient experience for a user. Our proposed Trajectory Efficiency metric (rubric score per step) makes this gap explicit. Making progress on Odysseys will therefore require not only higher ceilings on success rate but also more efficient trajectories. Promising directions for shortening trajectories and wait-time include multi-action batching per LLM call, delegating independent sub-goals to parallel sub-agents that can explore multiple sites concurrently, and explicitly training or prompting agents to optimize for score-per-step rather than overall score alone.
These limitations reflect deeper challenges in long-context planning, maintaining coherence across sites, and reliably executing extended workflows. Improving computer-use agents on long-horizon tasks, whether through reinforcement learning, inference-time search, or the efficiency-oriented techniques above, is a promising direction for future work. We release Odysseys tasks, rubrics, and analysis publicly; we believe the combination of realistic task design and fine-grained evaluation will help drive future progress on computer-use agents that can operate robustly over extended time horizons.