Odysseys
Benchmarking Web Agents on Realistic Long Horizon Tasks
Carnegie Mellon University · *Equal contribution
Existing web agent benchmarks have largely converged on short, single-site tasks that frontier models are approaching saturation on. However, real-world web use consists of long-horizon, multi-site workflows. Common tasks such as comparing products across different domains, planning trips across multiple services, or summarizing information from multiple search queries require sustained context and cross-site reasoning over potentially hours of browsing.
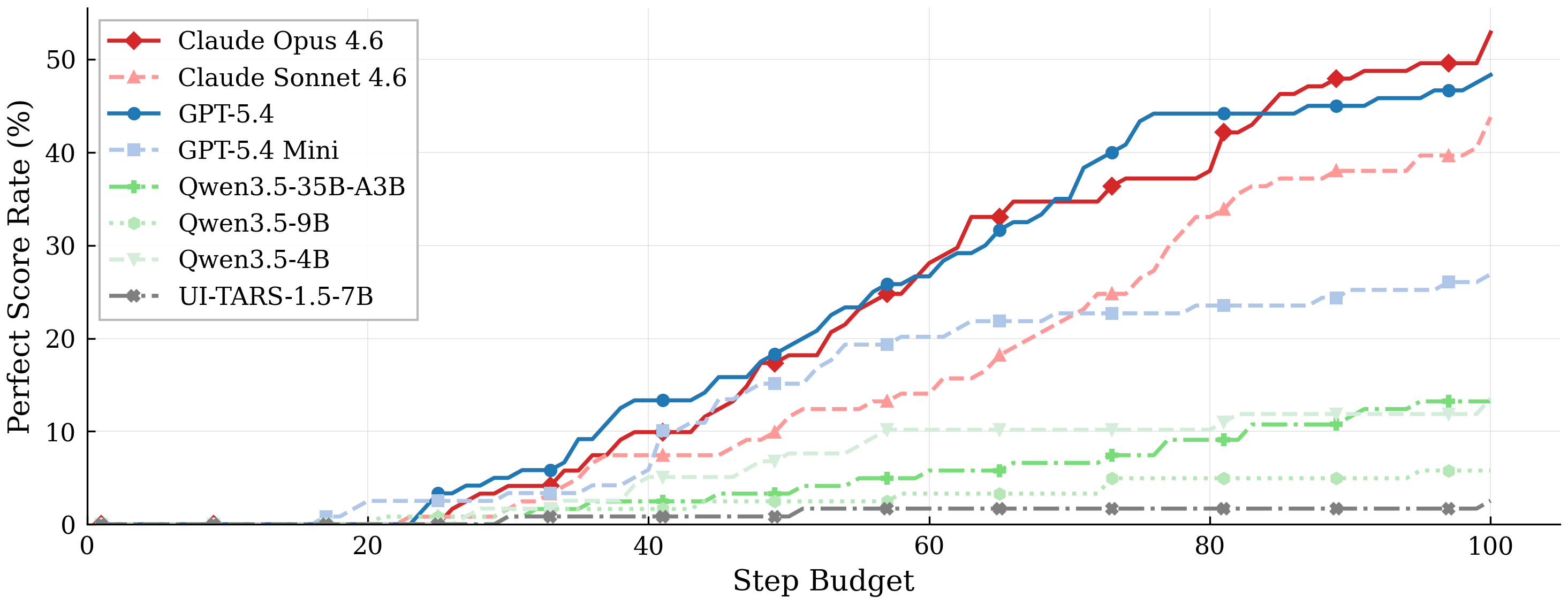
To capture and evaluate such behaviors, we introduce Odysseys, a benchmark of 200 long-horizon web tasks derived from real-world browsing sessions and evaluated on the live Internet. We find that binary pass/fail evaluation is inadequate for long-horizon settings and introduce a rubric-based evaluation, annotating each task with a set of graded rubric checkpoints that yields higher agreement with human judgment than commonly used trajectory-level LLM-as-a-judge metrics. We evaluate several leading frontier models and find that the strongest achieves 44.5% perfect task success, leaving substantial headroom. Beyond success rate, we argue that efficiency is a first-class concern for long-horizon agents and introduce a Trajectory Efficiency metric (rubric score per step) on which even frontier agents reach only 1.15%.
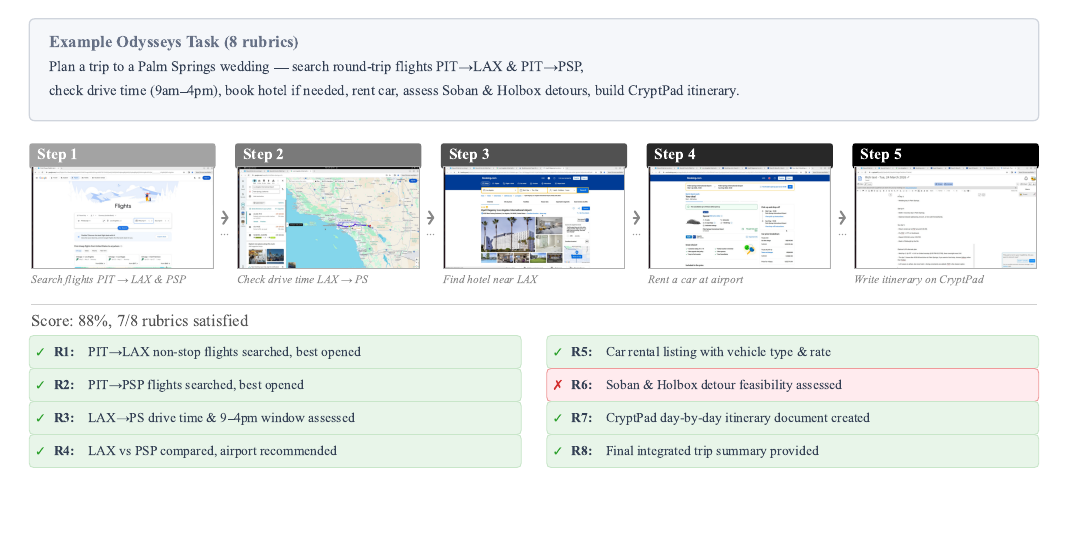
Example task
Each task is a first-person request that a user might realistically give a computer-use agent. Tasks are paired with rubric items that decompose progress into verifiable checkpoints.
Example trajectories
Recordings of frontier agents executing Odysseys tasks. Pick a task to watch the full browser session.
Full task prompt given to the agent
Headline result
Performance scales with step budget but plateaus well short of full completion. All models show a broadly sigmoidal curve; frontier API models climb steeper and higher, but none approach the ceiling.